基于Kubernetes的AI算力平台——分布式训练篇
为什么需要分布式训练?随着模型规模越来越大:尤其对于LLM,ChatGPT3 拥有1750亿个参数。业界认为340亿参数量才具备智能涌现的能力。训练的数据集越来越大模型规模足够大,一张GPU卡无法全部装载。数据集大,训练时间随着变大。此时需要引入分布式训练,解决上述的问题,以及加速模型的训练速度。并行策略(任务拆分)分
作者:user
为什么需要分布式训练?
随着
- 模型规模越来越大:尤其对于LLM,ChatGPT3 拥有1750亿个参数。业界认为340亿参数量才具备智能涌现的能力。
- 训练的数据集越来越大
模型规模足够大,一张GPU卡无法全部装载。数据集大,训练时间随着变大。此时需要引入分布式训练,解决上述的问题,以及加速模型的训练速度。
并行策略(任务拆分)
分治的思想,将问题分成多个子问题,每个子问题可以在不同的处理器上独立计算。对于模型训练,一般分为数据并行、模型并行、组合并行。
数据并行
所谓数据并行,就是将数据集分为N份(N等于GPU的数量)。每份数据集分片分配到一张GPU卡。每个GPU卡持有一个完整的模型副本,基于被分配的数据集分片进行训练。
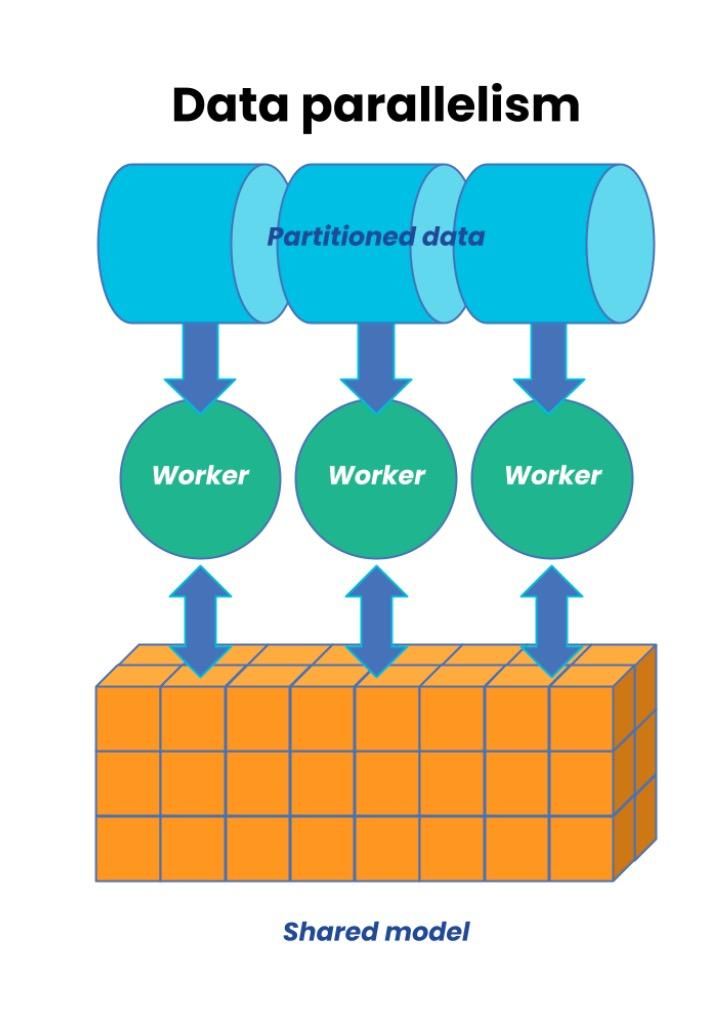
因为每张GPU需要装载整个模型副本,实际上,数据并行解决了大数据集的问题。对于大模型,就需要考虑模型并行的方案。
模型并行
模型并行,即将模型进行切分,将不同的模型切片分配到不同的GPU卡上基于全部数据集训练。
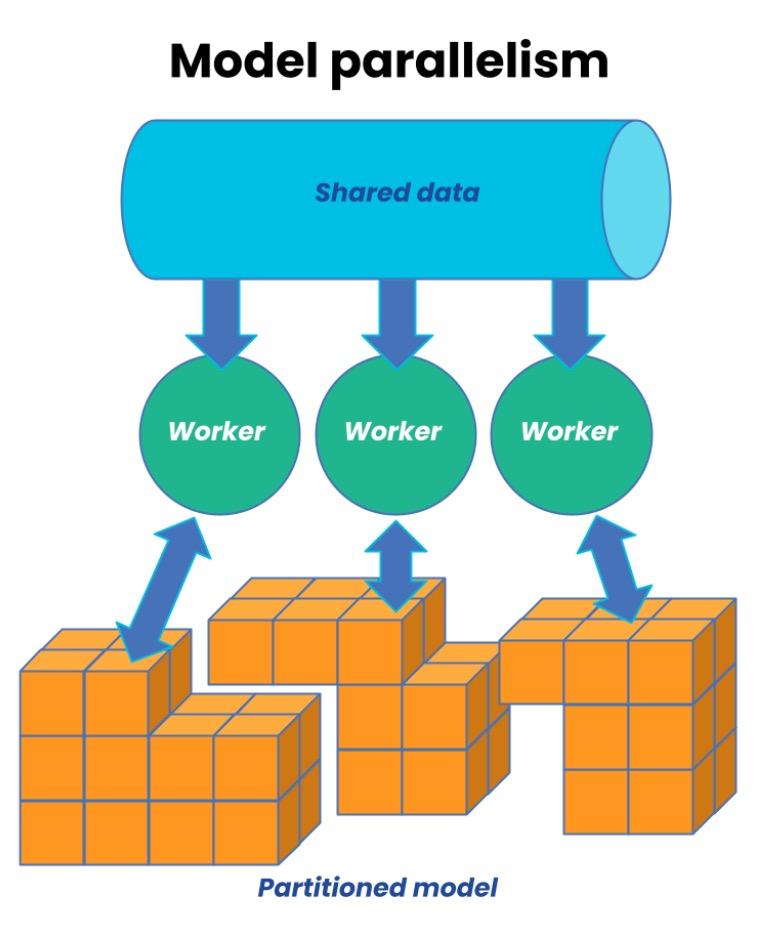
模型并行,实际上切分模型的维度,分为:
- 张量并行:按照张量的维度来切分,不同的GPU运行一个张量的不同部分。如矩阵乘法。
- 流水线并行:按照模型层的维度来切分,不同的GPU运行不同的层。
组合并行
灵活组合多种并行策略,比如下述的3D并行。
应对千亿以及万亿参数规模大模型,微软在DeppSpeed中实现了3D并行策略,3D = 数据并行 + 流水线并行 + 张量切片并行。3D 并行提高了内存和计算效率。
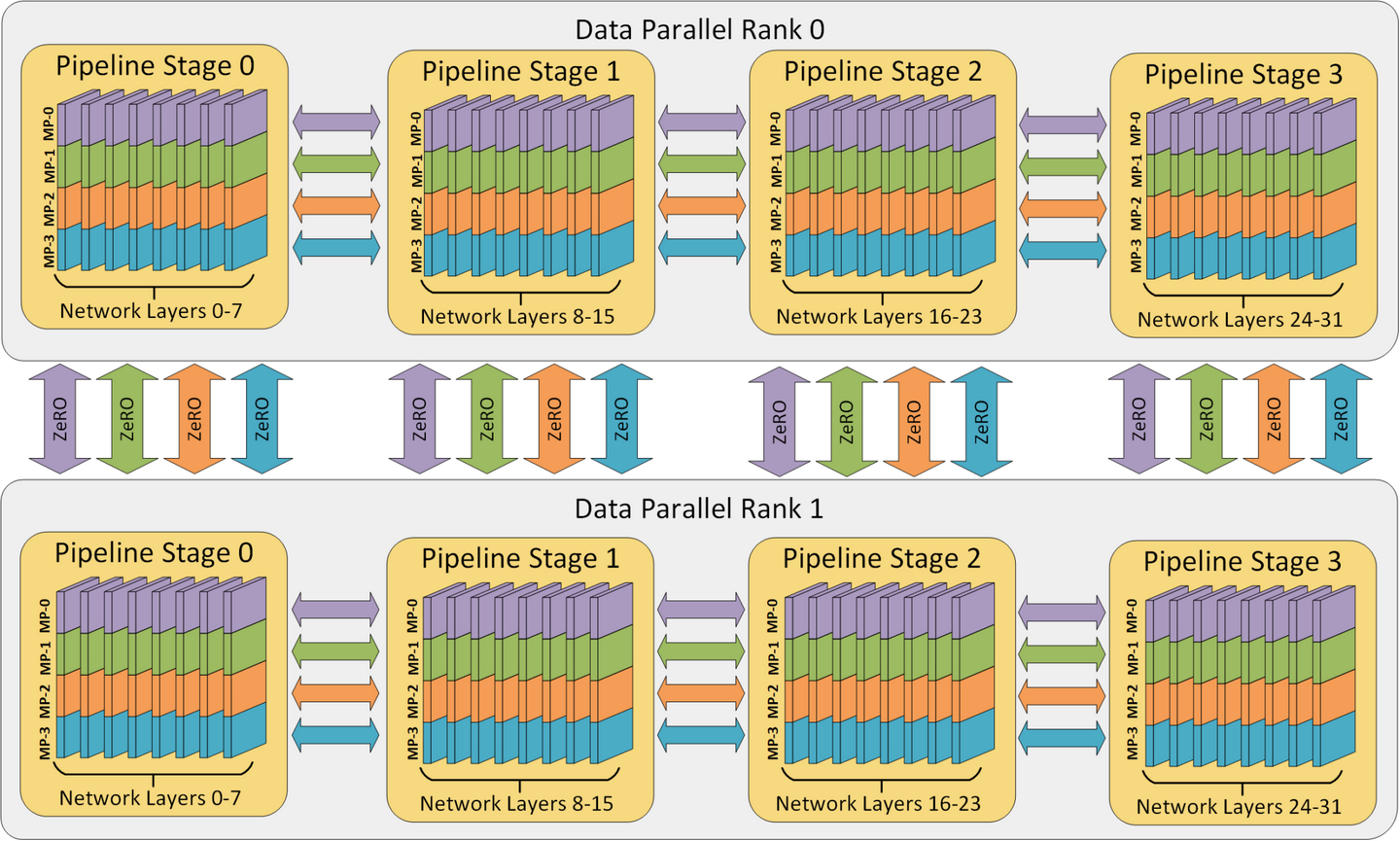
图 1:具有 32 个worker的3D并行示例。神经网络的层被划分为四个流水线阶段。每个流水线阶段内的层在四个模型并行worker之间进一步划分。最后,每个流水线跨两个数据并行实例进行复制,ZeRO 将优化器状态跨数据并行副本进行分区。
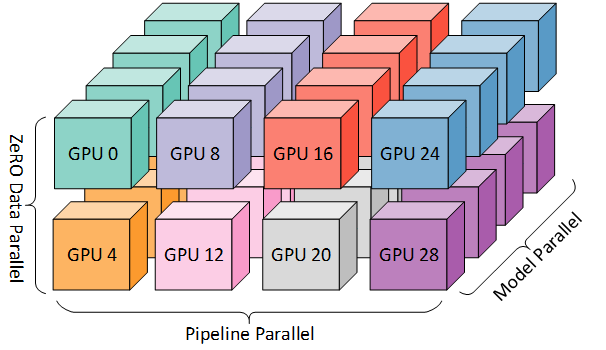
图 2:图 1 中的 worker 映射到系统上的 GPU,该系统具有八个节点,每个节点具有四个 GPU。着色表示同一节点上的 GPU
方案
技术领域没有银弹,分布式训练解决了大模型、大数据集的问题,也带来了一些其他的问题需要解决,比如数据同步、集合通信、加速通信等等。只有解决了这些问题,才能充分发挥分布式训练的优势。
集合通信以及加速
多机多卡环境下,需要引入高性能集合通信库,来支持集合通信原语以及感知worker之间网络拓扑进而加速通信。业界主要是OpenMPI、NCCL和 Gloo。
比如NCCL
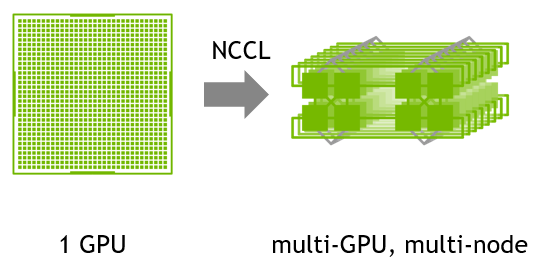
NVIDIA 集合通信库 (NCCL) 可实现针对 NVIDIA GPU 和网络进行性能优化的多 GPU 和多节点通信。NCCL 提供了 all-gather、all-reduce、broadcast、reduce、reduce-scatter、point-to-point send 和 receive 等集合通信原语,这些实现均经过优化,可通过节点内的 PCIe 和 NVLink 高速互联以及节点间的 NVIDIA Mellanox 网络实现高带宽和低延迟。
因为NCCL则是NVIDIA基于自身硬件定制的,做了很多优化,如果GPU选择英伟达的GPU,NCCL的效果往往比其它的通信库更好。
数据同步
一般来说是两种方案:Parameter Server(PS) 和 All Reduce。
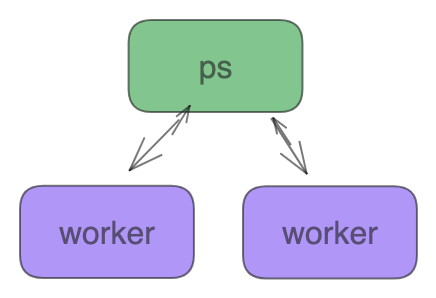
- Parameter Server 架构(就是常见的PS架构,参数服务器)
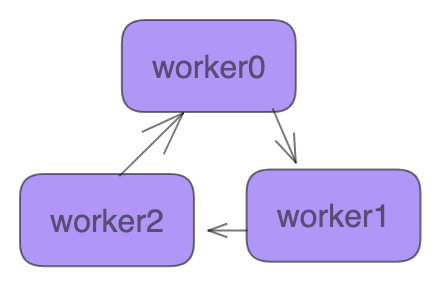
- All Reduce架构(常见的ring-allreduce)
Parameter Server 架构是一种中心化的架构。集群中的节点被分为两类:parameter server 和 worker。其中parameter server 存放模型的参数,而 worker 负责计算参数的梯度。在每个迭代过程,worker 从 parameter sever 中获得参数,然后将计算的梯度返回给 parameter server,parameter server 聚合从 worker 传回的梯度,然后更新参数,并将新的参数广播给 worker。
All Reduce架构,是一种去中心化架构,也是一种集合通信的架构。集群中所有的节点都是 worker,组成一个环。在一个迭代过程,每个worker 完成自己的 mini-batch 训练,计算出梯度,并将梯度传递给环中的下一个 worker,同时它也接收从上一个 worker 的梯度。对于一个包含N个 worker 的环,各个 worker 需要收到其它N-1个 worker 的梯度后就可以更新模型参数。
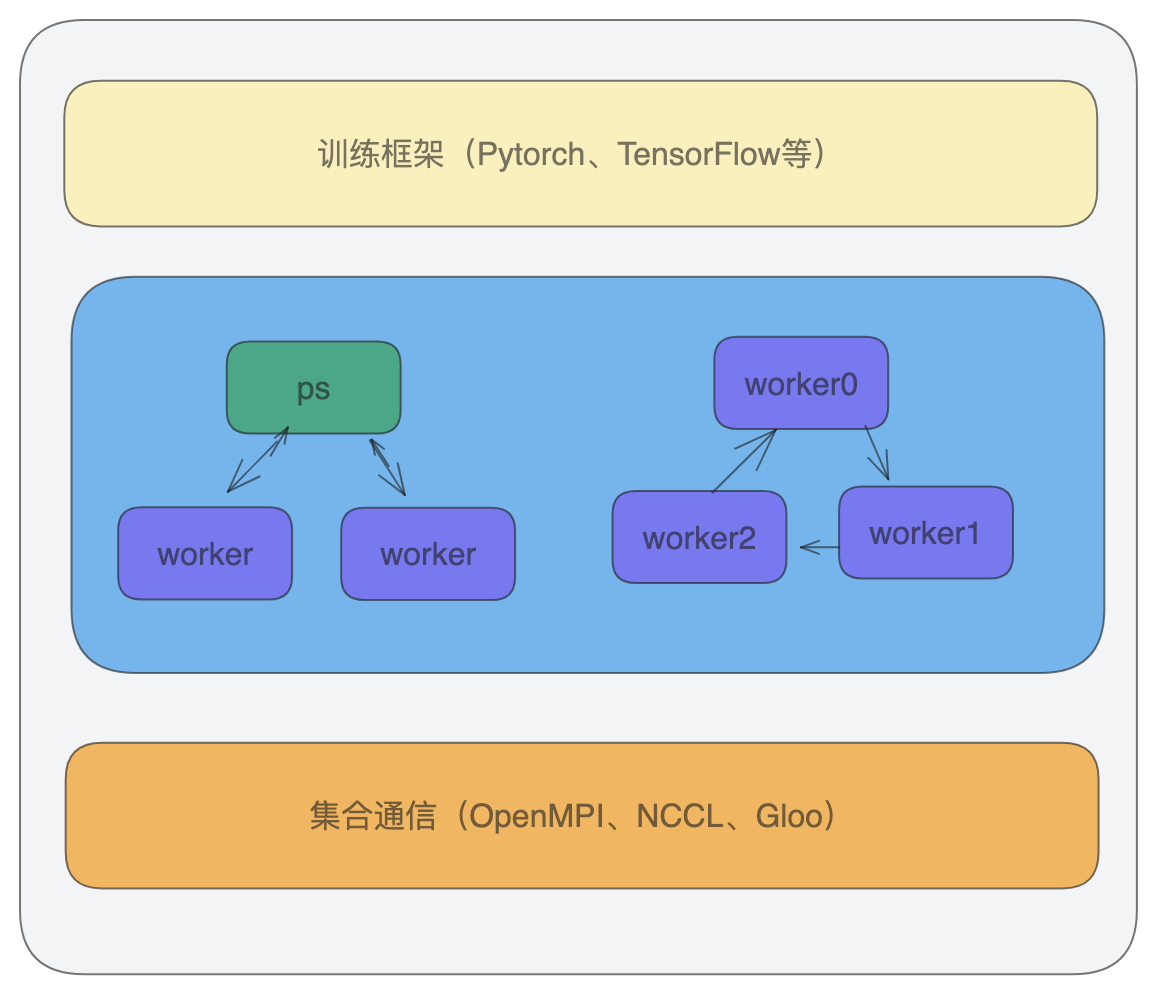
训练框架
训练框架提供用户友好的API、集成了集合通信库,支持按照用户设置的并行策略进行分布式训练。
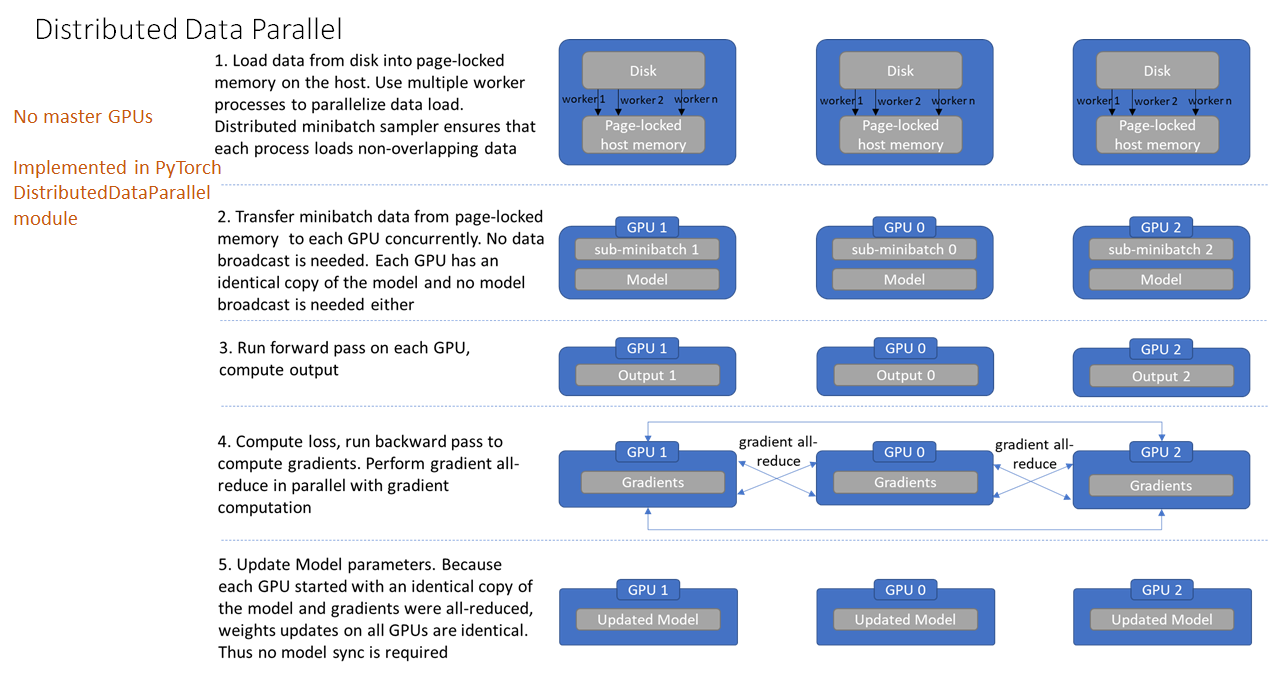
比如 Pytorch 提供了DataParallel (DP)和DistributedDataParallel(DDP)。
DistributedDataParallel流程图如下:
训练作业管理
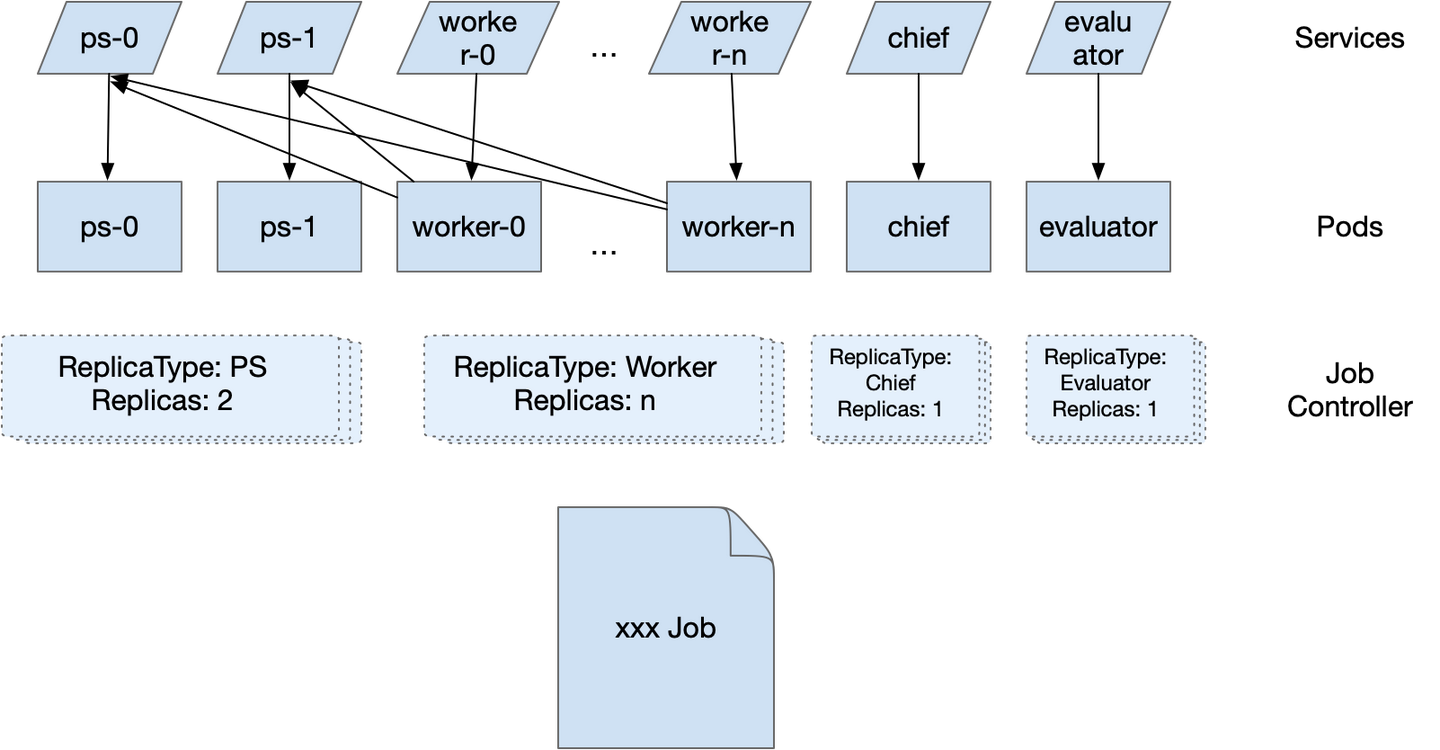
因为我们是基于Kubernetes实现算力平台,所以使用 Kubeflow Training Operator 项目来管理分布式训练作业,该项目支持常见的训练框架, 比如TensorFlow/PyTorch/Apache MXNet/XGBoost/MPI等。Operator 主要的工作包括:
- 在 Kubernetes 集群上创建 Pod 以拉起各个训练进程
- 配置用作服务发现的信息以及创建相关 Kubernetes 资源(如 Service)
- 监控并更新整个任务的状态
总结
本文简单介绍了分布式训练相关内容。实际的分布式训练包括更多内容,比如优化、容错、以及弹性训练等。
随着大模型流行,提升分布式训练的弹性能力也成为一个重要的研究方向。
Oobleck: Resilient Distributed Training of Large Models Using Pipeline Templates
Varuna: Scalable, Low-cost Training of Massive Deep Learning Models
Bamboo: Making Preemptible Instances Resilient for Affordable Training of Large DNNs
以上方案,旨在提升训练的容错性以及弹性能力,可以充分利用云上低成本的Spot算力。整个弹性训练,需要框架层和资源调度层协同工作。